[번역] 수직적 코드베이스 (The Vertical Codebase)
I
Inkyu Oh
SW Engineering•2026.04.14
이 게시글은 비공개(Draft) 상태입니다.AI 번역 결과는 완벽하지 않을 수 있습니다. 편집 페이지에서 내용을 검토하고 수정한 후 발행해주세요.
Dominik - 2026년 4월 13일

우리는 항상 코드베이스를 "제대로" 구조화하는 방법에 대해 나름의 의견을 가지고 있습니다. 대부분의 엔지니어가 그럴 것이라 생각합니다. 시간이 흐르고 상황이 변함에 따라 저의 입장도 분명 진화해 왔지만, 2년 전 제가 올린 트윗 중 지금도 100% 동의하는 내용을 발견했습니다.
Dominik 🔮 @tkdodo 많은 코드베이스에서 components / hooks / types / utils (그리고 constants)로 나누는 방식을 보게 되는데, 저는 이 방식을 가장 싫어합니다. 이는 도메인이 아니라 '타입'별로 그룹화하는 방식이기 때문입니다. "useTheme"은 ThemeProvider 옆이 아니라 "useTodo" 옆에 놓이게 되는데... 도대체 왜일까요?
정말 왜 그럴까요? 🤔 수평적 분할(Horizontal split)은 저에게 전혀 납득되지 않았습니다. 프로젝트를 처음 시작할 때는 편리할지 모르겠지만, 그게 전부입니다. 어차피 작성하는 대부분은
components일 것이고, 다른 폴더들은 파일 몇 개만 들어있을 뿐입니다.물론 시간이 지나면 이는 악몽이 되며, 일단 이런 구조가 자리 잡으면 벗어나기가 매우 어렵습니다. 이번에도 Sentry의 코드베이스가 좋은 예시가 되겠네요. 10년 넘게 이런 구조로 제품을 개발한 결과, 최상위 components 디렉터리(새 윈도우에서 열기)에는 200개가 넘는 파일이 쌓였습니다. 이 파일들의 공통점은 무엇일까요? 그저 '컴포넌트'라는 것뿐입니다. 그 외에는 아무것도 없습니다.
analyticsArea부터 workflowEngine까지 모든 것이 그 안에 들어있습니다. 사실, 어디서부터 찾아야 할지 알 수 없기 때문에 아무것도 찾지 못할 가능성이 큽니다.만약 여러분의 스타트업이 NGMI(성공하지 못할 것)라면, 구조는 아마 중요하지 않을 것입니다. 어쩌면 그래서 대부분의 사람들이 이를 문제라고 생각하지 않는 것일 수도 있습니다. 몇 년 후의 모습이 어떨지 상상하지 못하기 때문이죠. 하지만 일단 "성공한" 위치에 서게 된다면, 코드베이스가 규모 확장(Scale)과 성장을 견뎌낼 수 있도록 조치를 취하는 것이 좋은 생각입니다. 그리고 수평적 구조를 없애는 것이 그 시작으로 좋습니다.
하지만 AI는 신경 쓰지 않지 않나요?
어떤 엔지니어들은 에이전트가 작성, 리뷰, 수정 등 모든 일을 완전히 자동화된 방식으로 처리하기 때문에 더 이상 코드를 보지 않기도 합니다. 만약 여러분이 기술 부채에 허덕이더라도 다음 모델이 모든 것을 버리고 주말 사이에 다시 작성해 줄 것이라고 굳게 믿는 진영에 속해 있다면, 이 블로그 포스트는 아마 여러분을 위한 것이 아닐 것입니다. 하지만 코드를 읽지 않는다면 블로그 포스트도 읽지 않을 테니, 이는 애초에 겹치는 부분이 없는 벤 다이어그램 같네요. 여기까지 읽고 계신다면 여러분은 분명 코드를 중요하게 생각하시는 분일 것입니다.
Matt Pocock(새 윈도우에서 열기)은 지난주 AI Engineer Europe 행사에서 소프트웨어 기본기가 그 어느 때보다 중요한 이유(새 윈도우에서 열기)에 대해 훌륭한 강연을 했고, 저도 그의 의견이 옳다고 생각합니다.
제 생각에 에이전트가 효율적으로 일하기 위해 필요한 것은 인간과 거의 같습니다. 바로 경계(Boundaries), 제약(Constraints), 그리고 빠른 피드백 루프입니다. 여기에는 탐색하기 쉬운 프로젝트 구조, 린트(Lint) 규칙과 TypeScript의 훌륭한 설정, 그리고 빠르고 신뢰할 수 있는 테스트 스위트가 포함됩니다. 에이전트가 새로운 코드베이스에서는 매우 뛰어나지만, 수년간 유기적으로 성장해 온 코드베이스에서는 그리 효과적이지 못한 이유가 바로 이것입니다.
따라서 우리가 직접 코드베이스를 탐색할 필요가 없더라도, 우리는 여전히 구조에 신경을 써야 합니다.
코드 응집 (Code colocation)
중요한 것은 인지 부하(Cognitive Load)(새 윈도우에서 열기)이며, 코드베이스를 불필요하게 여기저기 옮겨 다녀야 하는 것은 인지 부하를 가중시킵니다. 함께 변경되는 코드는 함께 있어야 합니다. 제가 아는 대부분의 사람들은 컴포넌트의
props를 별도의 파일로 옮기지 않습니다. 보통 다음과 같이 작성하죠.export type WidgetProps = { id: string }export function Widget(props: WidgetProps) {}이것은 타당합니다. 컴포넌트를 읽거나 변경할 때 다른 곳으로 이동하지 않고도
props가 무엇인지 확인하고 싶기 때문입니다. 다른 곳에서 필요하다면 WidgetProps를 내보낼(export) 수도 있습니다.여전히 수평적 구조에서 이 파일은
src/components/widget.tsx에 위치할 것입니다. props는 컴포넌트의 필수적인 부분이자 공개 인터페이스이므로, 이러한 응집(Colocation)에 대해 두 번 생각하지 않을 것입니다. 이는 좋은 현상입니다.하지만 데이터 페칭(Data fetching)을 추가하면 어떻게 될까요?
export type WidgetProps = { id: string }export function Widget(props: WidgetProps) { const { data } = useSuspenseQuery(widgetQueryOptions(props.id))}widgetQueryOptions는 어디에 있어야 할까요? 유틸리티니까 src/utils/widget.ts 같은 곳에 있어야 할까요? 🤨규모 확장 (Scaling Up)
다시 말하지만, 코드가 많지 않을 때는 이 모든 것이 괜찮을 수 있지만, 규모가 커지면 감당할 수 없습니다. '규모 확장'이라는 말이 모호할 수 있지만,
components도 아니고 hooks도 아니라는 이유만으로 것들을 모아두는 utils 디렉터리는 상당히 임의적입니다.Sentry 코드베이스에는
components/analyticsArea와 논리적으로 결합된 함수들이 utils/analytics에 있습니다. utils/feedback에서 노출된 함수들은 오직 components/feedback 내부에서만 사용됩니다. profiling과 관련된 코드는 components/profiling, types/profiling, utils/profiling, views/profiling으로 쪼개져 있습니다. 이것이 과연 합리적일까요?결합도와 응집도 (Coupling and Cohesion)
우리가 원하는 것은 낮은 결합도와 높은 응집도(Low coupling and high cohesion)(새 윈도우에서 열기)입니다. 코드 간의 상호 의존성이 명확하고 모듈이 가능한 한 집중된 구조 말이죠. 수평적 분할은 정반대의 상황을 만듭니다. 모듈 간의 명확한 경계가 없고(어떤 컴포넌트든 어떤 유틸리티든 임포트할 수 있음), 서로 느슨하게만 연관된 코드들이 함께 살게 됩니다.
우리에게는 대안이 필요합니다.
수직적으로 정렬하기 (Align Vertically)
컴포넌트가 대중화되었을 때 우리가 JS, CSS, HTML에 어떤 일을 했는지 기억하시나요?
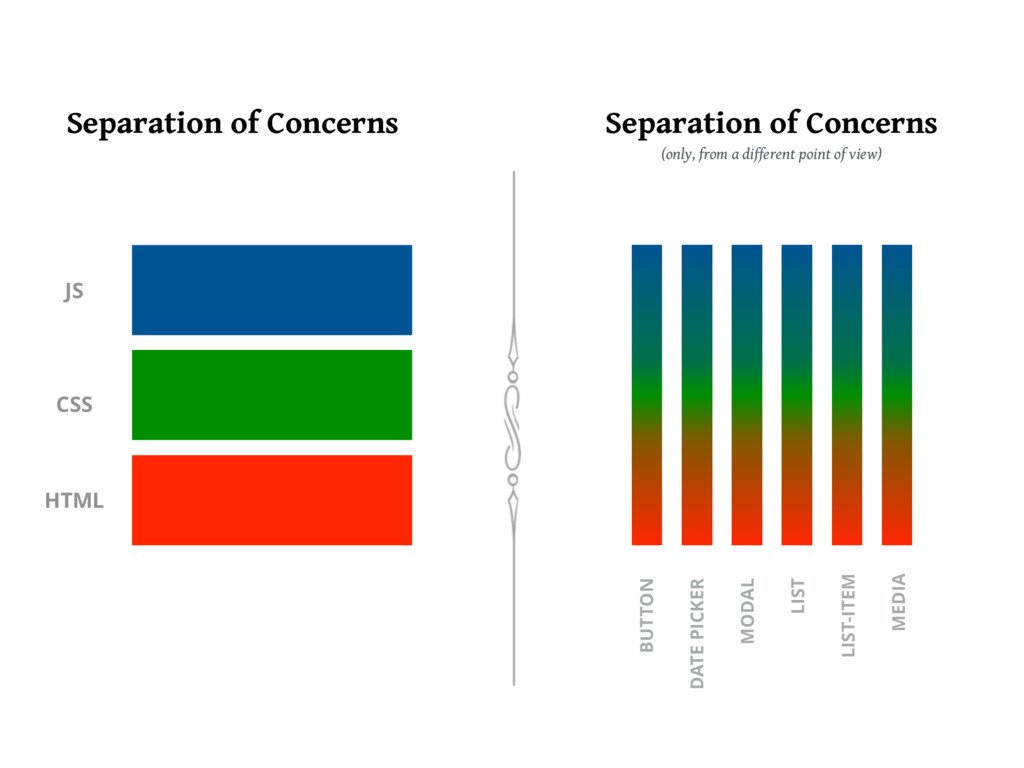
맞습니다. 우리는 그것들을 논리적으로 타당한 버킷(Bucket)에 함께 섞어 넣었습니다. 갑자기 버튼의 스타일과 버튼을 위한 JS가 함께 살게 되었습니다. 혁명적이었죠. 🎉
제품 팀 (Product Teams)
또한, 제가 일했던 대부분의 회사는 제품의 특정 부분을 처음부터 끝까지 책임지는 기능 팀(Feature team)에 제품 엔지니어들을 배치했습니다. "백엔드 엔지니어", "프론트엔드 엔지니어", "UX 팀"으로 나누지 않습니다. 대신 대시보드 팀, 리플레이 팀, 빌링 팀이 있고, 각 팀은 프론트엔드와 백엔드 엔지니어, 전담 디자이너와 제품 담당자로 구성됩니다. 그들은 자신의 도메인을 완전히 소유하며, 무엇을 어떻게 출시할지 결정합니다. 코드베이스도 이와 같이 구성하여 모든 팀이 "자신들의" 코드를 위한 전담 공간을 갖도록 하는 것이 타당할 것입니다.
그렇다면 코드베이스 구조화에 동일한 원칙을 적용하면 어떻게 될까요? JS와 CSS를 분리하지 않고, 프론트엔드와 백엔드 엔지니어를 분리하지 않는데, 왜 컴포넌트와 훅/유틸리티는 분리하는 걸까요?
올바른 수직 구조 찾기
모든 코드는 무언가를 수행합니다. 제발 그러길 바랍니다(새 윈도우에서 열기). 그렇지 않다면 존재할 이유가 없죠. 이상적으로는 코드가 무엇을 하는지 찾아내고, 논리적으로 유사한 코드끼리 그룹화할 수 있습니다.
widget과 관련된 모든 코드는 src/widgets/로 들어갑니다. 컴포넌트일 수도 있고, 훅, 타입, 유틸리티, 상수 등 무엇이든 될 수 있습니다. 기술적으로 무엇인지는 중요하지 않습니다. 오직 그것이 무엇을 하는지가 중요합니다.이는 종종 팀 구조 및
codeowners 설정 방식과 일치하며, 이는 좋은 부수 효과입니다. 예를 들어, 프로파일링 팀이 소유한 코드는 src/profiling/에 위치할 수 있습니다.이러한 그룹화는 수직적 구조를 만들어내며, 여러분이 무엇을 찾고 있는지 안다면 코드를 어디서 찾아야 할지 알 수 있을 뿐만 아니라, 함께 변경되는 코드들의 논리적 그룹을 형성하여 응집도를 높여줍니다.
하지만 올바른 수직적 그룹을 찾는 것은 어려운 일입니다. 이것은 정밀 과학이 아니기 때문에 도입하기가 더 어렵습니다. "컴포넌트는 여기, 타입은 저기"처럼 명확하게 나뉘지 않기 때문입니다. 실제로 무엇이 좋은 그룹화인지 고민해야 합니다.
논리적 그룹은 종종 라우트(Route)나 페이지와 결합되므로, 거기서부터 시작하는 것이 좋습니다.
/dashboard 페이지가 있다면 이 그룹부터 시작하세요. dashboard에 widgets가 있다면 그것들도 그곳에 들어갑니다. 만약 widgets가 충분히 커서 독자적인 수직 구조를 가질 만하다면, 특히 그 위젯들이 여러 라우트에서 사용된다면 별도로 분리할 수도 있습니다. 아마 /explore 페이지에서도 widgets를 생성할 수 있을 테니까요!이 구조를 제안할 때 항상 가장 먼저 나오는 질문입니다. 분명 모든 코드가 하나의 수직 구조에 들어갈 만큼 충분히 고립되어 있지는 않을 것입니다.
이미 힌트를 드렸듯이, 해결책은 보통 그것들을 별도의 수직 구조로 만드는 것입니다. 예를 들어, Sentry에는 여러 페이지에서 사용되는
PageFilters 컴포넌트가 있습니다. 이것은 보통 "기능(Feature)"이라고 부르는 것은 아닐지라도, 그 자체로 완벽하게 유효한 수직 구조이자 도메인입니다. 제가 이 용어(Feature)를 사용하는 것을 피한 이유이기도 합니다.현재 구조를 보면, 컴포넌트는
components/pageFilters(새 윈도우에서 열기)에 있고, 타입은 types/core(새 윈도우에서 열기)에 있습니다. 또한 utils/withPageFilters(새 윈도우에서 열기)에 유틸리티도 살고 있습니다. 😭 이는 pageFilters 관련 코드를 쉽게 찾을 수 없고, 명확한 소유권도 없으며, 작은 변경조차 먼저 여기저기 뒤져봐야 한다는 것을 의미합니다.경계 (Boundaries)
코드를 하나의 수직 구조로 모으는 것은 즉시 응집도를 높여주지만, 결합도를 자동으로 줄여주지는 않습니다. 단일 기능을 위해 유틸리티를 만들었다가 나중에 예상치 못한 곳에서 재사용되고 있음을 발견하여, 작은 변경조차 위험해지는 상황을 한두 번 겪은 게 아닙니다.
이를 해결하기 위해 경계가 필요합니다. 수직 구조의 어떤 부분이 다른 수직 구조에서 소비되도록 의도된 것인지, 어떤 부분이 "프라이빗(Private)"한 것인지 선언하는 방법이 필요합니다. 즉, 공개 인터페이스가 필요합니다.
모노레포 (Monorepos)
이를 달성하는 가장 좋은 방법은 모노레포로 이동하는 것입니다. 모든 수직 구조는 레포지토리 내에서 자체 패키지가 되고, 자체 의존성을 가지며, 공개 인터페이스는
package.json의 exports(새 윈도우에서 열기) 필드에 정의됩니다. 이제 수직 구조들은 서로 의존할 수 있지만, 그 관계는 명시적이 됩니다. 저는 pnpm workspaces(새 윈도우에서 열기)가 이 작업에 꽤 좋다는 것을 알게 되었습니다.또한 특정 수직 구조가 다른 구조에 의존하지 못하도록 규칙을 만들 수도 있습니다. Nx는 이를 기본적으로(새 윈도우에서 열기) 지원하지만, 구조를 만들기 위해 반드시 모노레포가 필요한 것은 아닙니다. Sentry에서는 어떤 부분이 무엇에 의존할 수 있는지 강제하기 위해 eslint-plugin-boundaries(새 윈도우에서 열기)를 사용하기 시작했습니다. 예를 들어, ESLint 에러를 발생시키지 않고는 우리 scraps 디자인 시스템의 프라이빗 유틸리티를 심층 임포트(Deep import)(새 윈도우에서 열기)할 수 없습니다.
함정은 무엇인가요?
세상에 공짜 점심은 없으므로 다음과 같은 어려움이 있습니다.
- 각 코드 조각에 대해 올바른 수직 구조를 선택하는 것은 어렵습니다.
- "프라이빗" 코드를 두면 여러 팀이 동일한 것을 처음부터 다시 구현할 위험이 있습니다.
두 지점 모두 팀 간의 더 많은 소통을 요구하며, 그렇습니다, 그것이 소프트웨어 엔지니어로서 정말 어려운 부분입니다. 언제나 그랬죠. 이것이 쉬울 것이라고 말한 적은 없지만, 저의 조언은 여전히 동일합니다. 코드베이스를 수직적으로 구축하세요. 나머지는 자연스럽게 따라올 것입니다.
0
2
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!