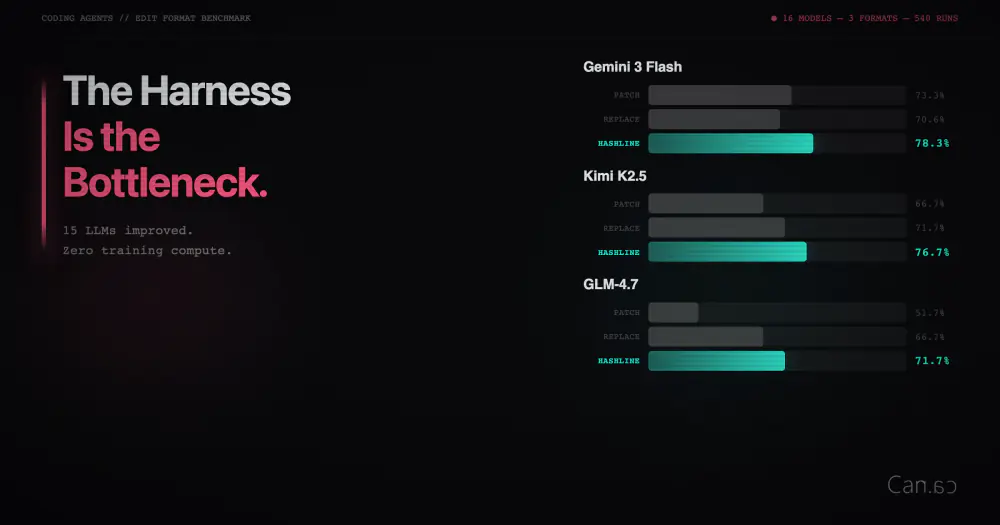
GraphQL: 엔터프라이즈의 허니문은 끝났다
John James
저는 실제 엔터프라이즈급 애플리케이션에서 몇 년 동안 GraphQL, 특히 Apollo Client와 Server를 사용해 왔습니다.
장난감 같은 앱이 아닙니다. 이제 막 시작한 스타트업의 프로젝트도 아닙니다. 여러 팀, BFF(Backend for Frontend), 다운스트림 서비스, 관측 가능성(Observability) 요구 사항, 그리고 실제 사용자가 존재하는 제대로 된 프로덕션 환경이었습니다.
그 모든 시간을 보낸 후, 저는 꽤나 지루한 결론에 도달했습니다.
GraphQL은 실제적인 문제를 해결하지만, 그 문제는 사람들이 인정하는 것보다 훨씬 더 지엽적(niche)입니다. 대부분의 엔터프라이즈 환경에서 그 문제는 이미 다른 곳에서 해결되었으며, 트레이드오프(Tradeoff)를 합산해 보면 GraphQL은 종종 순손실(Net negative)로 귀결되곤 합니다.
이 글은 "GraphQL은 나쁘다"는 글이 아닙니다. "허니문 기간이 끝난 후의 GraphQL"에 대한 글입니다.
GraphQL이 해결하려는 것
GraphQL이 해결하고자 하는 주요 문제는 오버페칭(Overfetching, 과도한 데이터 호출)입니다.
아이디어는 간단하고 매력적입니다.
- 클라이언트는 정확히 필요한 필드만 요청합니다.
- 더도 말고 덜도 말고 딱 필요한 만큼만요.
- 낭비되는 바이트가 없습니다.
- 새로운 UI 요구 사항이 생길 때마다 백엔드를 변경할 필요가 없습니다.
이론적으로는 훌륭합니다. 하지만 실제로는 상황이 훨씬 더 복잡합니다.
오버페칭은 이미 BFF에 의해 해결되었습니다
대부분의 엔터프라이즈 프론트엔드 아키텍처에는 이미 BFF가 존재합니다.
BFF는 구체적으로 다음과 같은 목적을 위해 존재합니다.
- UI에 맞게 데이터 형태를 가공
- 여러 다운스트림 호출을 집계(Aggregate)
- 백엔드의 복잡성을 은닉
- UI가 필요로 하는 정확한 데이터만 반환
BFF 뒤에서 REST를 사용하고 있다면, 오버페칭은 이미 해결 가능한 문제입니다. BFF는 응답 범위를 좁히고 UI가 관심을 갖는 내용만 반환할 수 있습니다.
네, GraphQL도 이 일을 할 수 있습니다. 하지만 사람들이 간과하는 부분이 있습니다.
대부분의 다운스트림 서비스는 여전히 REST라는 점입니다.
따라서 이제 여러분의 GraphQL 레이어는 여전히 다운스트림 REST API로부터 데이터를 오버페칭해야 하며, 그 후 응답의 형태를 다시 잡아야 합니다. 오버페칭을 제거한 것이 아닙니다. 단지 한 레이어 아래로 옮겼을 뿐입니다.
이 사실 하나만으로도 GraphQL의 주요 판매 포인트는 크게 퇴색됩니다.
여기서 GraphQL이 승리하는 경우가 있긴 합니다. 여러 페이지가 동일한 엔드포인트를 호출하지만 약간씩 다른 필드가 필요한 경우, GraphQL을 사용하면 쿼리별로 해당 차이점을 조절할 수 있습니다.
하지만 이 거래에 대해 솔직해져 봅시다.
여러분은 보통 요청당 몇 개의 필드를 아끼기 위해 다음과 같은 대가를 치르고 있습니다.
- 더 많은 설정
- 더 많은 추상화
- 더 많은 간접 참조(Indirection)
- 유지 관리해야 할 더 많은 코드
고작 몇 킬로바이트를 아끼기에는 매우 비싼 대가입니다.
구현 시간이 REST보다 훨씬 더 많이 소요됩니다
GraphQL은 REST BFF보다 구현하는 데 훨씬 더 오랜 시간이 걸립니다.
REST를 사용하면 일반적으로 다음과 같이 합니다.
- 다운스트림 서비스 호출
- 응답 적응(Adapt)
- UI가 필요한 데이터 반환
반면 GraphQL을 사용하면 이제 다음과 같은 작업을 해야 합니다.
- 스키마(Schema) 정의
- 타입(Type) 정의
- 리졸버(Resolver) 정의
- 데이터 소스 정의
- 어쨌든 어댑터 함수 작성
- 스키마, 리졸버, 클라이언트를 동기화 상태로 유지
GraphQL은 생산 속도를 희생하여 소비(Consumption)를 최적화합니다.
엔터프라이즈 환경에서는 이론적인 우아함보다 생산 속도가 더 중요합니다.
기본적으로 관측 가능성이 더 나쁩니다
이 부분은 충분히 논의되지 않고 있습니다.
GraphQL은 다음과 같은 기묘한 상태 코드 관습을 가지고 있습니다.
- 쿼리를 파싱할 수 없으면 400
- 실행 중 무언가 실패했지만
errors배열이 있으면 200
- 성공했거나 부분적으로 성공했으면 200
- 서버에 도달할 수 없으면 500
관측 가능성 측면에서 이는 고통스럽습니다.
REST의 경우:
- 2XX는 성공을 의미합니다.
- 4XX는 클라이언트 오류를 의미합니다.
- 5XX는 서버 오류를 의미합니다.
대시보드를 2XX로 필터링하면 해당 요청들이 성공했음을 알 수 있습니다.
하지만 GraphQL에서는 200이 여전히 부분적 또는 전체적 실패를 의미할 수 있습니다.
네, Apollo를 사용하면 이 동작을 커스터마이징할 수 있습니다. 하지만 바로 그게 포인트입니다. REST가 기본적으로 제공하는 것을 얻기 위해 추가 설정, 추가 관습, 그리고 추가적인 멘탈 모델(Mental model) 비용을 끊임없이 지불해야 합니다.
이것은 블로그 포스트를 읽을 때가 아니라, 장애 대응(On-call) 중일 때 정말 중요하게 다가옵니다.
캐싱은 직접 겪어보기 전까지만 환상적입니다
Apollo의 정규화된 캐싱(Normalized caching)은 진심으로 인상적입니다.
이론적으로는요. 실제로는 취약합니다.
단 하나의 필드만 다른 두 개의 쿼리가 있다면, Apollo는 이를 별개의 쿼리로 취급합니다. 그러면 여러분은 다음과 같이 수동으로 연결해 주어야 합니다.
- 기존 필드는 캐시에서 가져오도록
- 다른 필드만 새로 가져오도록
그 시점에서:
- 여전히 네트워크 왕복(Roundtrip)이 발생합니다.
- 더 많은 코드가 추가되었습니다.
- 캐시 문제 디버깅 자체가 하나의 커다란 일이 됩니다.
반면, REST는 기꺼이 몇 개의 필드를 더 오버페칭하고, 전체 응답을 캐싱한 뒤 다음 단계로 넘어갑니다. 추가 킬로바이트는 저렴합니다. 복잡성은 저렴하지 않습니다.
ID 요구 사항은 누수된 추상화입니다
Apollo는 기본적으로 모든 객체가
id 또는 _id 필드를 가질 것으로 기대하며, 그렇지 않으면 커스텀 식별자를 설정해야 합니다.이러한 가정은 많은 엔터프라이즈 API에서 유효하지 않습니다.
수많은 API들이:
- ID를 반환하지 않습니다.
- 자연스러운 고유 키가 없습니다.
- 전역적으로 식별 가능한 엔티티로 모델링되어 있지 않습니다.
그래서 이제 BFF는 단지 GraphQL 클라이언트를 만족시키기 위해 로컬에서 ID를 생성해야 합니다.
이는 다음을 의미합니다.
- 더 많은 로직
- 더 많은 필드
- 어쨌든 항상 하나의 추가 필드를 더 가져오게 됨
원래 목표가 오버페칭을 줄이는 것이었다는 점을 생각하면 아이러니한 일입니다.
REST 클라이언트는 이런 종류의 제약을 강요하지 않습니다.
파일 업로드와 다운로드가 어색합니다
GraphQL은 단순히 바이너리 데이터에 적합하지 않습니다.
실제로 여러분은 결국 다음과 같이 하게 됩니다.
- 다운로드 URL을 반환합니다.
- 그다음 어쨌든 파일을 가져오기 위해 REST를 사용합니다.
PDF와 같은 대용량 페이로드를 GraphQL 응답에 직접 포함하는 것은 응답 비대화와 성능 저하로 이어집니다.
이것 하나만으로도 "단일 API"라는 스토리는 깨집니다.
온보딩이 더 느립니다
대부분의 프론트엔드 및 풀스택 개발자들은 GraphQL보다 REST에 훨씬 더 익숙합니다.
GraphQL을 도입한다는 것은 다음을 가르쳐야 함을 의미합니다.
- 스키마 교육
- 리졸버 교육
- 쿼리 구성 교육
- 캐싱 규칙 교육
- 에러 시맨틱(Semantics) 교육
이러한 학습 곡선은 특히 팀이 빠르게 움직여야 할 때 마찰을 일으킵니다.
REST는 지루하지만, 지루한 것은 확장이 매우 잘 됩니다.
에러 처리가 필요 이상으로 어렵습니다
GraphQL의 에러 응답은... 이상합니다.
다음을 고려해야 합니다.
- Nullable vs Non-nullable 필드
- 부분 데이터(Partial data)
- Errors 배열
- 커스텀 상태 코드가 포함된 Extensions
- 어떤 리졸버가 왜 실패했는지 추적해야 할 필요성
이 모든 것이 간접 참조를 추가합니다.
이를 다음과 같은 단순한 REST 설정과 비교해 보십시오.
- 입력 유효성 검사 실패 시 400 반환
- 백엔드 실패 시 500 반환
- Zod 에러, 끝.
단순한 에러가 우아한 에러보다 이해하기 훨씬 쉽습니다.
최종 결과
GraphQL은 분명히 유효한 사용 사례를 가지고 있습니다.
하지만 대부분의 엔터프라이즈 환경에서:
- 여러분은 이미 BFF를 가지고 있습니다.
- 다운스트림 서비스는 REST입니다.
- 오버페칭은 여러분의 가장 큰 문제가 아닙니다.
- 관측 가능성, 신뢰성, 그리고 속도가 더 중요합니다.
모든 것을 종합해 볼 때, GraphQL은 종종 좁은 범위의 문제를 해결하면서 더 넓은 범위의 새로운 문제들을 도입하는 결과로 끝납니다.
이것이 제가 수년간 프로덕션에서 사용해 본 뒤 드리는 말씀입니다.
GraphQL은 나쁘지 않습니다. 단지 지엽적일 뿐입니다. 그리고 여러분에게는 아마 필요 없을 것입니다.
특히 여러분의 아키텍처가 이미 GraphQL이 설계된 목적이었던 그 문제를 해결했다면 더더욱 그렇습니다.
0
26
댓글
?
아직 댓글이 없습니다.
첫 번째 댓글을 작성해보세요!
Inkyu Oh님의 다른 글
더보기
번역
at:// 프로토콜을 아시나요?
Inkyu Oh • Back-End
2
0
98

React Compiler의 소리 없는 실패 (그리고 해결 방법)
Inkyu Oh • Front-End
0
0
21
번역
React Server Components 성능 입문
Inkyu Oh • Front-End
0
0
43
파란 바 없이
Inkyu Oh • SW Engineering
0
0
21